93.04分!安天澜砥大模型再次登顶CyberSec-Eval评测TOP1
时间:2025年10月22日
10月21日,安天澜砥威胁检测分析垂直大模型(N2-1021版本)以93.04分再次登顶CyberSec-Eval动态评测榜,并在加密技术与密钥管理、AI与网络安全、漏洞管理与渗透测试、供应链安全、安全架构设计评测中取得五个单项第一名或与单项第一持平成绩。
澜砥大模型是安天研发的模型族,主干模型VILLM (Virus Inspection Large Language Model)由安天全面自研,可处理二进制字节数据、进行威胁检测分析,支持最长336M的超长上下文分析;另外两个分支模型SecOpsGPT(大安)侧重自然语言处理与多模态数据理解、SecDevGPT(小元)侧重程序代码补全,分支模型基于开源模型改造并使用社区权重进行迁移学习训练,分别用于安全运营辅助和安全开发辅助。
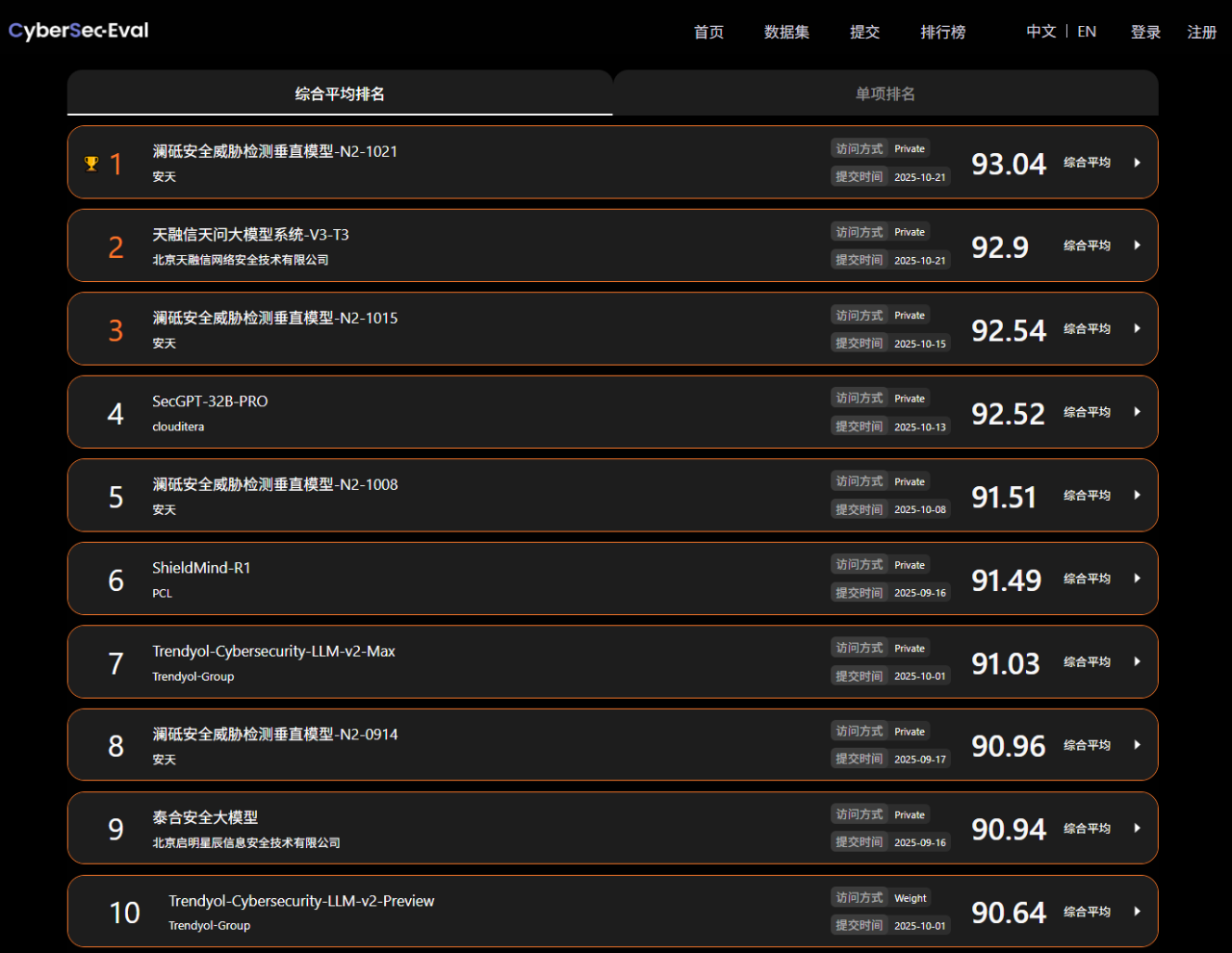
CyberSec-Eval综合排名TOP10
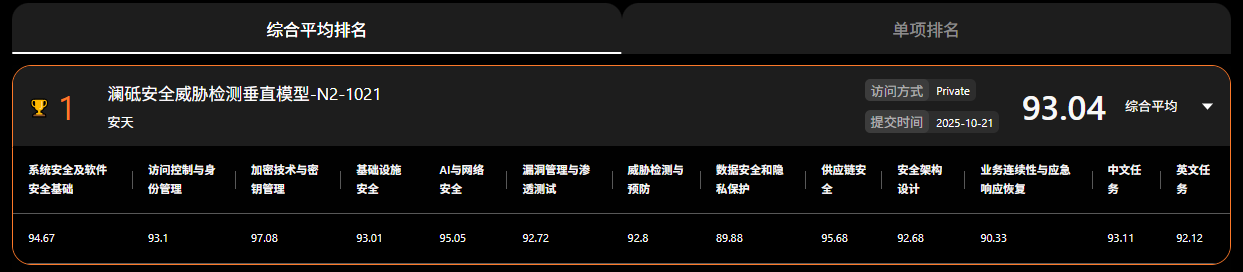
安天澜砥威胁检测垂直模型各分项得分情况
|
细分领域 |
单项最高分 |
安天澜砥单项得分 |
单项排名 |
|
系统安全及软件安全基础 |
96.67 |
94.67 |
3 |
|
访问控制与身份管理 |
95.02 |
93.1 |
2 |
|
加密技术与密钥管理 |
97.08 |
97.08 |
1 |
|
基础设施安全 |
93.51 |
93.01 |
2 |
|
AI与网络安全 |
95.05 |
95.05 |
1 |
|
漏洞管理与渗透测试 |
92.72 |
92.72 |
1 |
|
威胁检测与预防 |
93.36 |
92.8 |
4 |
|
数据安全和隐私保护 |
92.26 |
89.88 |
4 |
|
供应链安全 |
95.68 |
95.68 |
1 |
|
安全架构设计 |
92.68 |
92.68 |
2 与第一同分 |
|
业务连续性与应急响应恢复 |
93.33 |
90.33 |
3 |
|
中文任务 |
93.11 |
93.11 |
1 |
|
英文任务 |
92.12 |
92.12 |
1 |
安天澜砥单项分数、排名和与最高分对比表(单项排名第一或持平的为红色)
附:安天澜砥大模型参测CyberSec-Eval轨迹
9月9日,安天团队澜砥大模型-SecOpsGPT子模型首次提交测试并于次日公开,平均分综合成绩88.3分,排名第三,并取得3个单项的第一名或与第一名同分。
10月8日,基于VILLM+SecOpsGPT整合为澜砥大模型N2,提交N2-1008版本测试以91.51的平均分综合成绩排名第一登顶,并取得四个单项的第一名或与第一名同分。
10月13日,其他参测方新提交取得92.52分,排名降为第二。团队持续训练模型、调整优化提示词。
10月15日,提交N2-1015版本,以92.54分重回榜单第一名,成绩保持到10月20日。
10月21日,伴随其他参测方新的提交,排名降至第二。团队持续训练模型、调整优化提示词,提交N2-1021版本。
10月22日,澜砥N2-1021提交通过审核,以93.04分再回榜首,并取得五个单项的第一名或与第一名同分。