安天发布VILLM威胁分析垂直大模型丨第九届军博会
时间:2024年05月18日
在第九届中国(北京)军事智能技术装备博览会上,安天发布了VILLM威胁分析垂直大模型,能有效赋能威胁分析和防御场景,提升网空对抗场景中感知能力、提升以执行体为主要对象的敌我识别的精确性,缩短完成响应处置威胁所需的时间,降低应对威胁所需的知识储备和心智负担,改善网络安全防御和响应的自动化与智能化水平,实现“新质生产力保障新质战斗力”。
安天VILLM威胁分析垂直大模型
安天自研的VILLM (Virus Inspection Large Language Model)模型族,属于生成式模型,不受传统分类模型的分类数量限制,具备更强的理解能力和分析能力。
模型基于安天赛博超脑20余年积累的海量样本特征工程数据训练而成。通过安天AVL SDK引擎多维度静态向量的提取能力和安天追影威胁分析系统集群部署形成的动态向量和网络特征,对其关键结果进行解析、抽象、计算和提取,得到VILLM模型所需要的向量级威胁情报数据。其数据包括文件识别信息、判定信息、属性信息、结构信息、行为信息、主机环境信息、数据信息等,支持对不同场景下向量特征进行威胁判定和输出详实的知识理解,并形成应用不同需求和场景的多形态的检测方式,提升后台隐蔽威胁判定能力,进一步为安全运营赋能。同时,提升端点产品、流量产品、分析产品和态势感知等产品的场景化检测能力与知识输出能力,支撑对威胁的理解和响应处置。
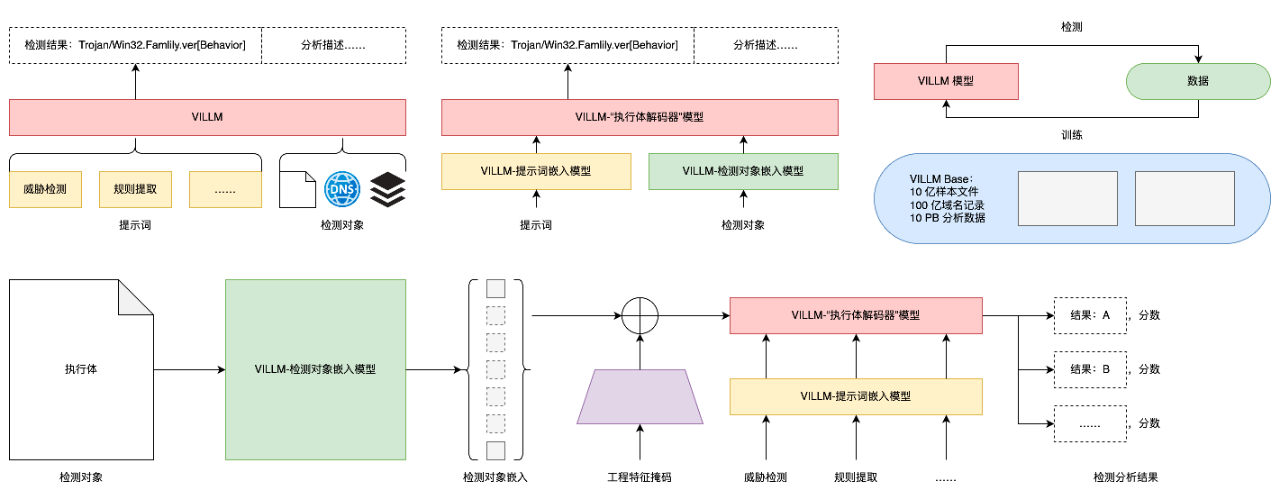
安天VILLM威胁分析垂直大模型的基本运行机理
安天VILLM模型族直接理解二进制数据、具备百倍于常规语言模型的上下文理解能力。恶意代码样本不同于一般意义的对象样本,既非图像、视频、音频等固定格式的静态文件,也非自然语言。其涉及近300种不同的文件格式,且绝大多数都是编译产生的二进制数据,而其中大量存在加壳、加密、感染正常样本等情况。因此其通过“贝叶斯”、“隐马尔可夫”等传统深度学习算法处理效果极差,也并不适用于以自然语言为输入的各种闭源和开源大模型。特别是恶意代码样本本身体积较大,很难在token和上下文受限的模型中使用。安天VILLM在安天引擎的格式识别和预处理能力与赛博超脑分析体系的支撑下,有效解决二进制数据直接理解、突破token和上下文长度限制等问题。
安天VILLM模型族与安天威胁检测的特征工程体系和品控指标有效对接。安天在威胁检测能力输出方面始终坚持超高检出能力、精准检测和极低误报三个标准。在检出能力方面为支撑将99%的恶意威胁阻断于首次连接/运行的能力导向。在精准检测方面,坚持不仅要区分有无恶意,也要准确精准提供被检测对象的命名,因此始终坚持严格的分类、家族精准命名体系(参见计算机病毒分类命名百科全书,virusview.net)。在误报控制方面,始终坚持在对系统、驱动和常见软件零误报基础上,对其他对象误报率不高于十万分之五。这也使多数传统深度学习算法和微调开源大模型的实现方式,基本无法和安天的特征工程和品控体系对接。安天VILLM模型族可以与安天AVL SDK叠加使用,不仅强化了检测能力,也可以在隔离或无法频繁获得安天升级的场景中,降低检测能力的衰减效应。而输出结果与安天引擎的报警格式保持一致,降低对日志处理接口的改造成本。特别是,不会产生其他深度学习算法和开源模型引入到来的敏感事件干扰。
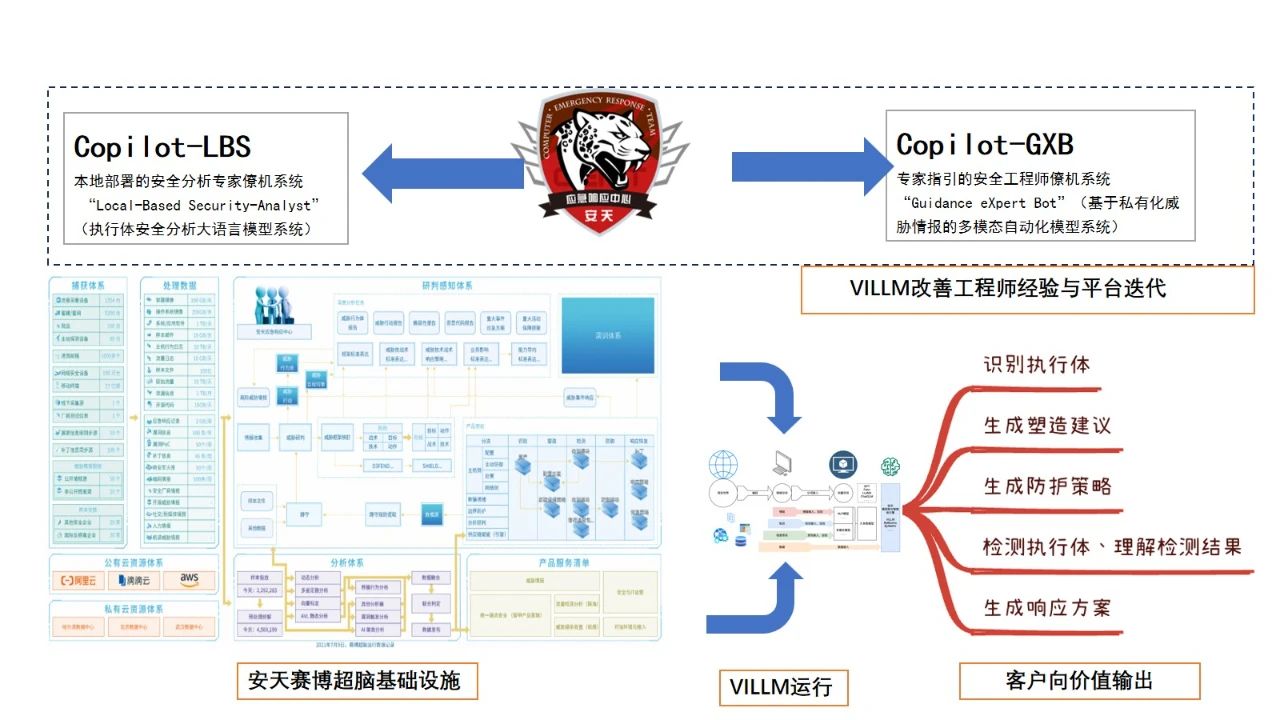
安天VILLM威胁分析垂直大模型的整体价值愿景
安天VILLM模型族设计基于 “叠加创新”的思维构建,在赛博超脑侧与安天特征工程和知识工程融合,提升特征工程和知识工程运行质量,在客户侧通过生成式技术,为威胁检测和分析产品提供更强的威胁鉴定能力和威胁知识输出能力。除执行体样本对象外,安天VILLM还专门适配威胁对抗和安全运营场景,特别改善了对强时序数据对象(如日志、网络数据流)的检测能力。在不同算力环境、不同网络联通或隔离条件下,既能发挥传统反病毒引擎体系的高速、精准、可弹性定制剪裁的优势,也在威胁的检测识别能力方面具有良好的泛化效果和鲁棒性。特别是考虑到当前的新的算力危机背景下,绝大多数客户本身难以承载独立的GPU算力体系建设成本。安天提供了接入赋能、低算力条件部署和独立算力建设三种方案。所需的算力显著低于常见开源模型,在能耗和使用成本方面具有明显优势。